library(tidyverse)Learning Objectives
From this topic, students are anticipated to be able to:
- recognize whether a given data set is ‘tidy’ or ‘untidy’ for their analysis
- understand why ‘tidy’ data can be useful
- reshape a data set between ‘long’ and ‘wide’ formats, using
tidyr::pivot_longer()andtidyr::pivot_wider() - understand how to grapple with explicit missing values created by pivoting
Resources
Video lecture for this topic:
Written resources on tidy data:
To learn how to use the
pivot_*()functions, consult tidyr’s pivot vignette.To get a better understanding of the concept of tidy data:
- Hadley Wickham’s paper on Tidy Data is the gold standard treatment of tidy data.
- A “code heavy” version of the tidy data paper is tidyr’s “Tidy Data” vignette.
Tidy Data and the Tidyverse
In the last two weeks, we learned about the dplyr package for data manipulation and the ggplot2 package for graphing. These two packages are part of the “tidyverse”: a collection of data science packages that are designed to have input data frames and output data frames that are tidy. In fact, we can load all packages in the tidyverse at once with the single command library(tidyverse).
Here, we are using the word “tidy” in a technical sense - we’re not talking about how “neat” or “organized” your data is. Instead, “tidy” is a very specific set of rules for storing data.

(Image attribution: “Tidy Data for reproducibility, efficiency, and collaboration” by Julia Lowndes and Allison Horst.)
Your turn: work with some untidy data
All of the data we used before this week were already tidy. This made it easy to use the tidyverse packages dplyr and ggplot2 to do what we needed to do. What happens when that’s not the case?
The fivethirtyeight R package contains a dataset called drinks. This dataset was compiled as part of a FiveThirtyEight article that explored (among other things) which countries consumes the most alcohol.
library(fivethirtyeight)
drinks_tbl1 <- as_tibble(drinks) %>% select(!total_litres_of_pure_alcohol)
head(drinks_tbl1)## # A tibble: 6 × 4
## country beer_servings spirit_servings wine_servings
## <chr> <int> <int> <int>
## 1 Afghanistan 0 0 0
## 2 Albania 89 132 54
## 3 Algeria 25 0 14
## 4 Andorra 245 138 312
## 5 Angola 217 57 45
## 6 Antigua & Barbuda 102 128 45The following graphic was made from the drinks dataset.

With a partner or a small group:
- Is it possible to reproduce the plots above using
drinks_tbl1and only thedplyrandggplot2packages? - What is tidy format here? Mentally (or with pen and paper, or even with a spreadsheet editor like Excel or Google Sheets) sketch out the format of the tidy tibble.
- How would you reproduce the plots above using the
ggplot2packages, given the data set in tidy format? - Does it take a lot of code and effort to carry out the reproduction?
Too easy? Then discuss the steps for how you would transform the first few rows of drinks_tbl1 from untidy to tidy “by hand”, i.e. not by using the tools from the tidyr package that we will learn about this week.
Tidy depends on the data analysis plan
“You better think (think) about what you’re trying to do …” - Aretha Franklin, “Think”
It’s clear from the definition that tidiness is an attribute of a dataset. But did you know that tidiness also depends on what you are planning to do with the data? That’s because what’s an observation and what’s a variable depends on the data analysis plan!
We will demonstrate using data from “The Great British Bake Off” compiled by Allison Hill in the R package bakeoff. The graphics that follow (and the code to produce the graphics) were lightly adapted from Allison’s Plot Twist talk.
First, let’s decide on some questions we can address with this data.
- How did viewership change as new series came out?
- The show moved channels after Series 7. Was viewership higher, lower, or about the same before and after the move?
These questions have implicitly defined our observations: they are individual units of the most granular populations we are trying to describe or compare. Here, the populations to be compared are series, and units within them are episodes. The variables now fall into place: they are measured attributes of our observations (episodes): episode number, viewership, series membership, etc. This means that the following representation of viewership data is tidy for the “change in viewership over series” analysis:
library(bakeoff)
ratings_tbl1 <- ratings %>%
mutate(ep_id = row_number()) %>%
select(ep_id, viewers_7day, series, episode)
head(ratings_tbl1)## # A tibble: 6 × 4
## ep_id viewers_7day series episode
## <int> <dbl> <dbl> <dbl>
## 1 1 2.24 1 1
## 2 2 3 1 2
## 3 3 3 1 3
## 4 4 2.6 1 4
## 5 5 3.03 1 5
## 6 6 2.75 1 6Every row is an observation (a unique episode), and the columns are variables (episode number across series, 7-day viewership, series, and episode number within series).
This is a typical example where the tidy format makes it easy to do our analysis. For example, to investigate these questions, we might make a bar plot of the number of viewers in millions within a 7-day window per episode, coloured by series. The following code uses the tidy tibble ratings_tbl1 to make this bar plot. Notice that it was easy to use our graphing environment of choice (ggplot2 in the tidyverse) to make the plot because our data is tidy, and the tidyverse is designed to work with tidy data.
series_labels <- ratings_tbl1 %>%
mutate(series=as.factor(series)) %>%
group_by(series) %>%
summarize(y_position = median(viewers_7day) + 1,
x_position = mean(ep_id))
# make the plot
ratings_tbl1 %>% mutate(series=as.factor(series)) %>%
ggplot(aes(x = ep_id, y = viewers_7day, fill = series)) +
geom_col(alpha = .9) +
ggtitle("7-Day Viewership across Series 1-10") +
geom_text(data = series_labels, aes(label = series,
x = x_position,
y = y_position)) +
theme_classic() +
scale_fill_manual(values = bakeoff_palette(),
guide = "none") +
xlab("Episode Number") +
ylab("7-Day Viewership (millions)")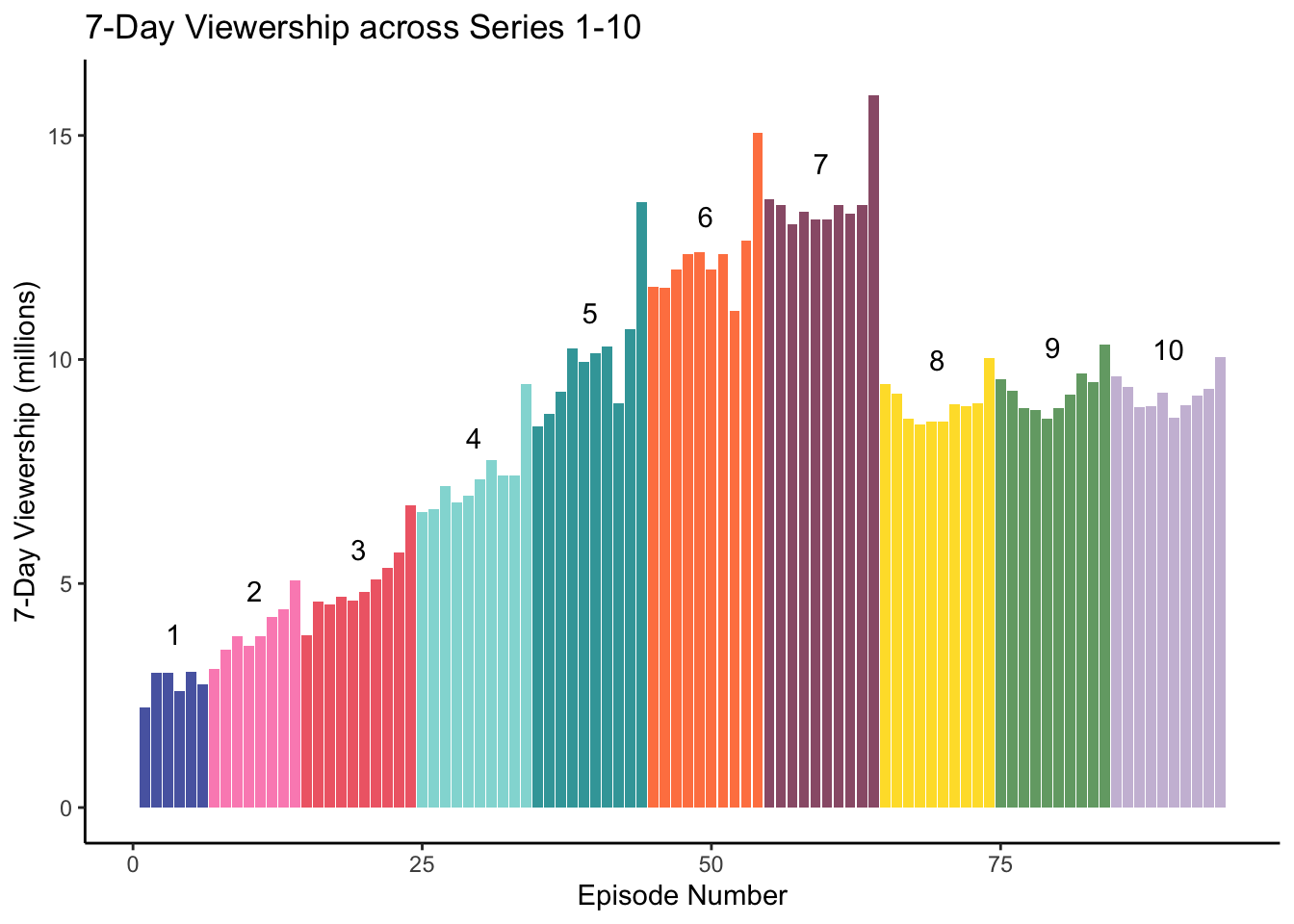
Your turn: what’s tidy now?
Now let’s consider a different set of questions:
- How did viewership grow between premiere to final episode in each series?
- Does the premiere-to-final-episode growth vary across series?
To investigate these questions, we might make a bar plot like the one below displaying percentage increase in the number of viewers in millions within a 7-day window from the premiere episode to finale episode for the first 10 series, using the tidy tibble ratings_tbl2.
ratings_tbl2 %>% mutate(pct_change = (last - first)/first) %>%
ggplot(aes(x = fct_rev(series), y=pct_change)) +
geom_col(fill = bakeoff::bakeoff_colors("baltic"), alpha = .5) +
labs(x = "Series", y = "% Increase in Viewers, First to Last Episode") +
ggtitle("% Increase in Viewers from Premiere to Finale") +
scale_y_continuous(labels = scales::percent) +
theme_classic() +
coord_flip() 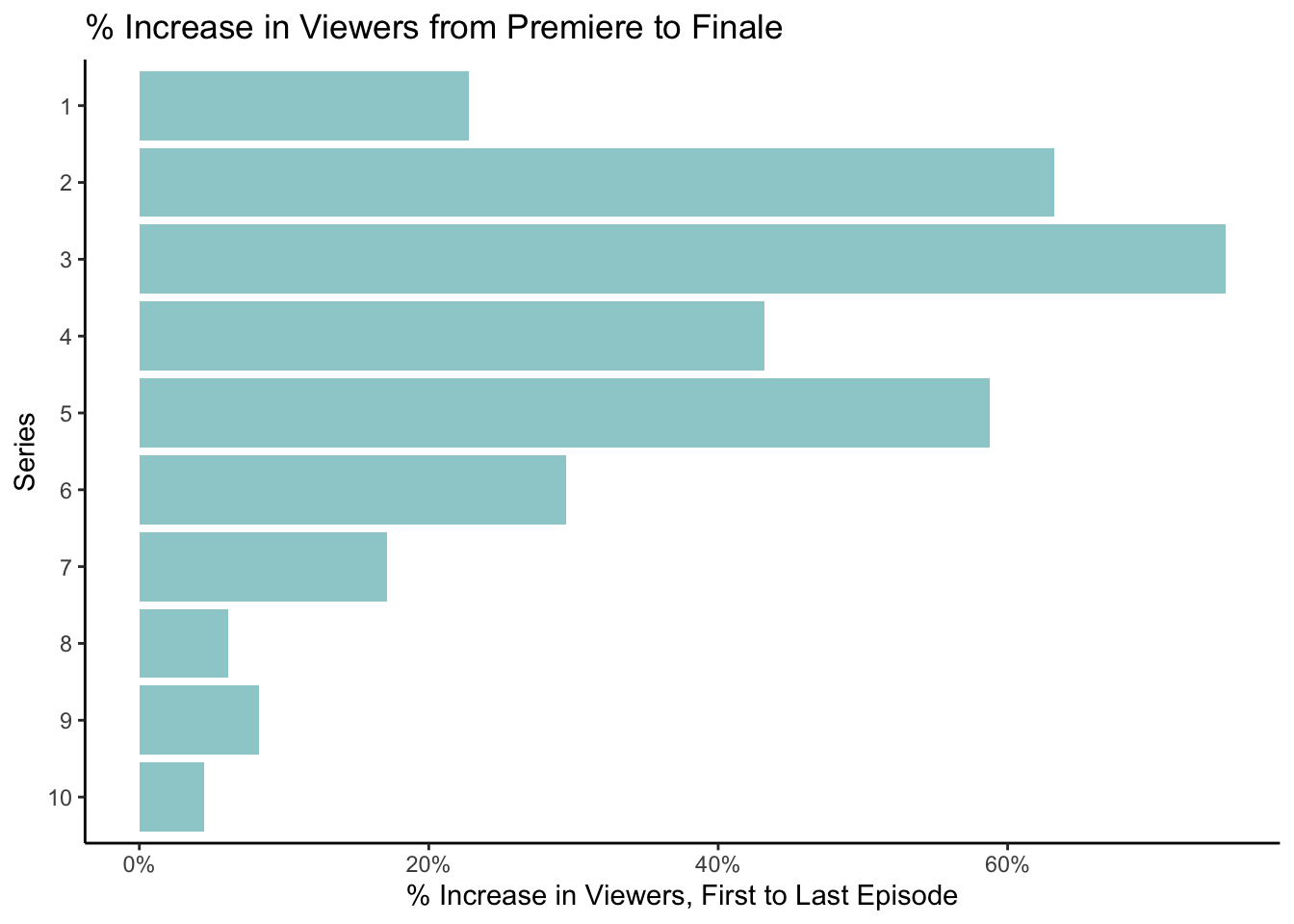
With a partner or a small group:
- What do you think
ratings_tbl2looks like? - Why is it tidy? (Hint: what are the observations and variables?)
- Could you have calculated the information in
ratings_tbl2usingratings_tbl1? (No need to write code - just discuss whether it’s possible.)
Pivoting for Tidying
Once you have figured out what’s tidy for you, you may come to realize that your data is not tidy. As we have discussed, it will typically save you time and frustration to tidy it before moving on in your analysis.
Very often this will involve using “pivoting” type functions. For example, the tidyr package in the tidyverse has two main pivoting functions:
pivot_longer()makes datasets longer: it moves some information in the columns into new rows, thereby increasing the number of rows of the dataset.
pivot_wider()makes datasets wider: it moves some information in the rows into new columns, thereby decreasing the number of rows of the dataset.
By now, you should have a sense for why this might be useful for tidying!
Pivoting Wider
Here is some code to create a variable for whether an episode is the first or last episode of the season to ratings_tbl1 and subset to only the data from the first and last episodes of each season.
ratings_tbl1 <- ratings_tbl1 %>%
group_by(series) %>%
filter(episode == 1 | episode == max(episode)) %>%
ungroup() %>%
mutate(episode_fl = recode(episode, `1` = "first", .default = "last"))
head(ratings_tbl1)## # A tibble: 6 × 5
## ep_id viewers_7day series episode episode_fl
## <int> <dbl> <dbl> <dbl> <chr>
## 1 1 2.24 1 1 first
## 2 6 2.75 1 6 last
## 3 7 3.1 2 1 first
## 4 14 5.06 2 8 last
## 5 15 3.85 3 1 first
## 6 24 6.74 3 10 lastThis is not the same format as ratings_tbl2, which was the tidy format for our earlier “viewership growth within series” analysis. But it does contain the same information. To finish converting ratings_tbl1 into ratings_tbl2, we need to make ratings_tbl1 wider: we need to move some information in the rows (the info about whether each episode is the first or last episode of each season) into new columns.
We can solve this problem using pivot_wider, which needs three pieces of information.
What is a set of columns that uniquely identifies each observation? Put their names in the
id_colsargument.Where should the names for the new columns come from? Put the name of the column you want to take the new variable names from in the
names_fromargument.What values should the new columns contain? Put the name of the columns you want to take the values from to
values_fromin thevalues_fromargument.
Note that if you don’t specify an id_cols argument, pivot_wider will assume that you want it to be every column except those in names_from and values_from.
ratings_tbl2 <- ratings_tbl1 %>%
pivot_wider(id_cols = series,
names_from=episode_fl,
values_from=viewers_7day)
head(ratings_tbl2)## # A tibble: 6 × 3
## series first last
## <dbl> <dbl> <dbl>
## 1 1 2.24 2.75
## 2 2 3.1 5.06
## 3 3 3.85 6.74
## 4 4 6.6 9.45
## 5 5 8.51 13.5
## 6 6 11.6 15.0Also note that any columns not included in id_cols, names_from, and values_from (e.g. ep_id) will simply be dropped.
If we wanted to keep the info in ep_id as well, we would add it to the values_from argument:
ratings_tbl1 %>%
pivot_wider(id_cols = series,
names_from=episode_fl,
values_from=c(viewers_7day, ep_id))## # A tibble: 10 × 5
## series viewers_7day_first viewers_7day_last ep_id_first ep_id_last
## <dbl> <dbl> <dbl> <int> <int>
## 1 1 2.24 2.75 1 6
## 2 2 3.1 5.06 7 14
## 3 3 3.85 6.74 15 24
## 4 4 6.6 9.45 25 34
## 5 5 8.51 13.5 35 44
## 6 6 11.6 15.0 45 54
## 7 7 13.6 15.9 55 64
## 8 8 9.46 10.0 65 74
## 9 9 9.55 10.3 75 84
## 10 10 9.62 10.0 85 94Pivoting Longer
The Basics: Column Names Contain Variable Values
Here is a snippet of WHO data on the number of tuberculosis cases in different years in different countries.
table4a## # A tibble: 3 × 3
## country `1999` `2000`
## <chr> <dbl> <dbl>
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766If we wanted to compare tuberculosis cases over time by country (e.g. by plotting the year on the x-axis and case count on the y-axis with a line for each country), then this format is not tidy. We want to (graphically) compare years within countries, so there should be one observation per unit within each population (country-years). In this case, we do not observe units within each country-year, so each observation is a country-year. The variables then fall into place: the country and year labels, and the case counts.
(Aside: if we had measured more data, then perhaps there would be more units within each population! Imagine if we had case-level information, like severity. Then we could view cases as observations within the country-year populations, and we would have variables like country, year, case ID, and severity.)
So the tidy format here puts the variables (the year, the country, and the case counts) on the columns. There are 6 rows, one for each unique country-year combination.
## # A tibble: 6 × 3
## country year cases
## <chr> <chr> <dbl>
## 1 Afghanistan 1999 745
## 2 Afghanistan 2000 2666
## 3 Brazil 1999 37737
## 4 Brazil 2000 80488
## 5 China 1999 212258
## 6 China 2000 213766Notice that compared to table4a, the tidy format is longer. That means to produce it using table4a, we need to lengthen it by moving some information in the column names (the info about the measurement year) into new rows.
We can solve this problem using pivot_longer, which needs three pieces of information.
Which are the columns that we want to expand into more rows? Put their names in the
colsargument.We want to save the information in the names of those columns as values in new column(s) of our dataset. What should we name these new column(s)? This is the
names_toargument.We also want to preserve the information in the values of those columns - so we should save them as values in a new column of our dataset. What should we name it? This is the
values_toargument.
table4a %>% pivot_longer(cols = c(`1999`, `2000`),
names_to = "year",
values_to = "cases")## # A tibble: 6 × 3
## country year cases
## <chr> <chr> <dbl>
## 1 Afghanistan 1999 745
## 2 Afghanistan 2000 2666
## 3 Brazil 1999 37737
## 4 Brazil 2000 80488
## 5 China 1999 212258
## 6 China 2000 213766Challenge 1: Column Names Contain Multiple Variable Values
Here’s a more realistic (but still simplified!!) look at the WHO Tuberculosis data.
who_demo <- who2 %>%
select(country, year, starts_with("sp")) %>%
rename_with(function(x)
str_remove(x, pattern="sp_"),
starts_with("sp")) %>%
filter(year %in% c(1999, 2000)) %>%
filter(country %in% c("Afghanistan", "Brazil", "China"))
head(who_demo)## # A tibble: 6 × 16
## country year m_014 m_1524 m_2534 m_3544 m_4554 m_5564 m_65 f_014 f_1524
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Afghanistan 1999 8 55 55 47 34 21 8 25 139
## 2 Afghanistan 2000 52 228 183 149 129 94 80 93 414
## 3 Brazil 1999 301 3662 5401 5827 4630 2634 2121 372 2909
## 4 Brazil 2000 1894 7268 11568 11906 8623 5085 4494 1859 6719
## 5 China 1999 1247 18961 29328 25095 24239 21564 21367 1431 15178
## 6 China 2000 1131 19111 29399 25206 25593 21429 21771 1420 14536
## # ℹ 5 more variables: f_2534 <dbl>, f_3544 <dbl>, f_4554 <dbl>, f_5564 <dbl>,
## # f_65 <dbl>This time, cases are broken down by gender (f/m) and by age range (014\1524\2534\3544\4554\5564\65).
Suppose now that we are interested in comparing tuberculosis rates over time across (potentially) gender, age, and country. Then the most granular population we are trying to describe is a country, gender, age, and year combination, and like in the last example, we have no measured sub-units within that population, so an observation is a unique combination of country, gender, age, and year. (What a mouthful!)
Once we’ve sorted that out, the variables fall into place: country, year, gender, age range, and case count. Values for gender and age range are currently located in the column names of who_demo, and values for case count are currently spread across multiple columns. So to tidy who_demo up, we need to use pivot_longer() to move the info in the columns into new rows.
Conceptually, this is pretty similar to the last example: we want to use the information in m_014, m_1524, etc. to create new rows. So we should put those column names into the cols argument. But now, we want the information in their column names - the gender and age - to go into two new columns: gender and age. We can do this by specifying two column names in the names_to argument: gender and age.
But how is pivot_longer() to know which part of the column name m_014 corresponds to the gender, and which part corresponds to the age? You need to tell it that the pieces of information are separated by the “_” character using the names_sep argument.
Finally, we can specify the name of the new column we want the values in the m_014, m_1524, etc. columns to go into with the values_to argument.
who_demo %>% pivot_longer(cols = !(country:year),
names_to = c("gender", "age"),
names_sep = "_",
values_to = "cases")## # A tibble: 84 × 5
## country year gender age cases
## <chr> <dbl> <chr> <chr> <dbl>
## 1 Afghanistan 1999 m 014 8
## 2 Afghanistan 1999 m 1524 55
## 3 Afghanistan 1999 m 2534 55
## 4 Afghanistan 1999 m 3544 47
## 5 Afghanistan 1999 m 4554 34
## 6 Afghanistan 1999 m 5564 21
## 7 Afghanistan 1999 m 65 8
## 8 Afghanistan 1999 f 014 25
## 9 Afghanistan 1999 f 1524 139
## 10 Afghanistan 1999 f 2534 160
## # ℹ 74 more rowsChallenge 2: Column Names Contain Variable Names And Values
So far we have seen examples where the column names contain variable values. But what if they contain names AND values?
Let’s have a look at the household dataset (loaded with the tidyr package), which has the date of birth and names of two children in families. Let’s say that we wanted to investigate how children names relate to their date of birth.
head(household)## # A tibble: 5 × 5
## family dob_child1 dob_child2 name_child1 name_child2
## <int> <date> <date> <chr> <chr>
## 1 1 1998-11-26 2000-01-29 Susan Jose
## 2 2 1996-06-22 NA Mark <NA>
## 3 3 2002-07-11 2004-04-05 Sam Seth
## 4 4 2004-10-10 2009-08-27 Craig Khai
## 5 5 2000-12-05 2005-02-28 Parker GracieWe are trying to learn about the population from which these children belong; it is hard to say precisely what that is without having more information about how this data was collected, but it is likely something like “all children living in a particular place in a particular year”. The units in this population are children. So to tidy this data, we’d want “date of birth” and “name” to be two variables/columns associated with an observation/row (a child). We know we want to use pivot_longer(), because we want to make household longer by creating new variables. But wait! The names of the “date of birth”/“name” variables AND the values of the “child” variable are BOTH in the column names of household!
Inspecting the documentation for pivot_longer() very carefully reveals that you can use a special specification of the names_to argument to resolve this problem.
household %>% pivot_longer(cols = -family,
names_to = c(".value", "child"),
names_sep = "_")## # A tibble: 10 × 4
## family child dob name
## <int> <chr> <date> <chr>
## 1 1 child1 1998-11-26 Susan
## 2 1 child2 2000-01-29 Jose
## 3 2 child1 1996-06-22 Mark
## 4 2 child2 NA <NA>
## 5 3 child1 2002-07-11 Sam
## 6 3 child2 2004-04-05 Seth
## 7 4 child1 2004-10-10 Craig
## 8 4 child2 2009-08-27 Khai
## 9 5 child1 2000-12-05 Parker
## 10 5 child2 2005-02-28 GracieThe special ".value" specification says that we want to use the first component of the pivoted column name as a variable name, and make a new column with values coming from the second component of the pivoted column name. The second thing we pass into names_to names that new column.
This process is best described by Figure 6.7 from R4DS.
But wait! Row 4 is a bunch of NAs! Does that mean this data isn’t tidy??
The fact that there is an NA does not necessarily mean that this data is untidy. To be clear: for the purpose of the tidy data definition, an indicator for a missing value is a value.
Whether this data is untidy depends on the data context. Essentially, the question we should ask is: “Is row 4 an observation that we are missing information about? Or is it simply an artifact of our pivoting procedure?”
Suppose this study was designed to only sample families with two children. Then, row 4 could be a real observation that we are missing information about: family 2 should have only been included if they had two children. Perhaps this reflects family 2 filling out a survey that asks them the number of children (in which they listed 2), but then getting distracted and forgetting to fill out the information for their second child. In this case, our data is tidy, and the tidy data format is a real advantage: it reveals missing information in our data set that was not obvious from the original untidy format.
Now suppose this study just samples families at large. We know from experience about the world that some families have one children, some families have two, and some families have more. Then, it seems possible that row 4 is not a real observation: family 2 might just have a single child. In this case, we have a row for something that is not an observation, so we would like to tidy up by dropping it. We could actually have done this by altering our original pivot_wider() call as follows:
household %>% pivot_longer(cols = -family,
names_to = c(".value", "child"),
names_sep = "_",
values_drop_na = TRUE)## # A tibble: 9 × 4
## family child dob name
## <int> <chr> <date> <chr>
## 1 1 child1 1998-11-26 Susan
## 2 1 child2 2000-01-29 Jose
## 3 2 child1 1996-06-22 Mark
## 4 3 child1 2002-07-11 Sam
## 5 3 child2 2004-04-05 Seth
## 6 4 child1 2004-10-10 Craig
## 7 4 child2 2009-08-27 Khai
## 8 5 child1 2000-12-05 Parker
## 9 5 child2 2005-02-28 GracieThis discussion highlights the importance of knowing the context in which your data is collected for tidying (and for your analysis at large). Here and elsewhere, it really pays to be in close contact with the people who generated your data.
Separating and Uniting for Tidying
The tidyr package has a function for gluing columns together (unite) and for cutting columns apart (separate). Why might this help us tidy? Here is another snippet of WHO Tuberculosis data.
table3## # A tibble: 6 × 3
## country year rate
## <chr> <dbl> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/1280428583The rate column contains the values of two variables: case counts and population counts. We would like to snip it apart at the “/” character to create two columns:
(table5 <- table3 %>% separate(col = rate,
into = c("cases", "population")))## # A tibble: 6 × 4
## country year cases population
## <chr> <dbl> <chr> <chr>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583The col argument specifies the column we want to separate,
and the into argument specifies the names of the new columns. The sep argument (not specified here) specifies where we want to cut. The default is pretty clever - it separates at any non-alphanumeric value. (How this is accomplished involves regular expressions, which are very useful when working with character data. We will learn more about regular expressions in STAT 545B. )
Your turn: learning to use tidyr
We think the best way to learn the basics of tidyr is to work through the first two parts of Worksheet A4.
First 30 minutes of Class 2
- Haven’t attempted all of the questions on the first two parts of Worksheet A4? Then spend this time attempting unattempted questions.
- Finished attempting all of the questions? Then do the optional R4DS Tidying reading, and maybe even do some of the exercises for extra practice.
During this time, teaching team will also walk around and answer questions and chat about anything tidy related.
Next 50 min in Class 2
Now’s your chance to ask about any questions you got stuck on and get them answered by the instructor!
Coda: The Merits of Untidy Data
As we’ve seen, tidy data is often very helpful. But there are also times when untidy data is good. Here are a few reasons:
- The format that lends itself best to fast computations might not be tidy. Case Study: Tidy Genomics.
- Untidy data is often easier for humans to interpret and edit. See Untidy Data: The Unreasonable Effectiveness of Tables.
- We could lose important information about the context in which the data was collected by cleaning and tidying raw data. This can have important ethical implications; see Chapter 5 of the book “Data Feminism” by Catherine D’Ignazio and Lauren F. Klein.
In summary, tidiness is a very useful concept, and tidying data is often useful. But we should remember that absolutes are few and far between in data science and statistics. Just because tidying data is often useful, doesn’t mean it’s always useful.
Attribution
Albert Y. Kim inspired the in-class exercises using the drinks data set from fivethirtyeight. Allison Horst and Julia Lowndes created the illustrated tidy data series. Alison Hill inspired the Great British Bakeoff example. We are immensely grateful to these people for creating amazing educational materials!
We would also like to thank Samantha Tyner for pointing us towards the Data Feminism book during her week as the curator of the @WomenInStat Twitter account.